Large language models are increasingly integrated with external environments, tools, and agents like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today’s LLM inference systems are designed for standalone LLMs. They treat each external interaction as the end of LLM generation and form a new request when the interaction finishes, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents InferCept, the first LLM inference framework targeting augmented LLMs and supporting the efficient interception of LLM generation. InferCept minimizes the GPU resource waste caused by LLM interceptions and dedicates saved memory for serving more requests.InferCept improves the overall serving throughput by 1.6x-2x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.
Preble: Efficient Distributed Prompt Scheduling for LLM Serving
Vikranth
Srivatsa, Zijian
He, Reyna
Abhyankar, and
2 more authors
Prompts to large language models (LLMs) have evolved beyond simple user questions. For LLMs to solve complex problems, today’s practices are to include domain-specific instructions, illustration of tool usages, and long context such as textbook chapters in prompts. As such, many parts of prompts are repetitive across requests, and their attention computation results can be reused. However, today’s LLM serving systems treat every request in isolation, missing the opportunity of computation reuse.
This paper proposes Preble, the first distributed LLM serving platform that targets and optimizes for prompt sharing. We perform a study on five popular LLM workloads. Based on our study results, we designed a distributed scheduling system that co-optimizes computation reuse and load balancing. Our evaluation of Preble on two to 8 GPUs with real workloads and request arrival patterns on two open-source LLM models shows that Preble outperforms the state of the art avg latency by 1.5x to 14.5x and p99 by 2x to 10x.
@article{srivatsa2024preble,title={Preble: Efficient Distributed Prompt Scheduling for LLM Serving},author={Srivatsa, Vikranth and He, Zijian and Abhyankar, Reyna and Li, Dongming and Zhang, Yiying},year={2024},journal={arXiv preprint arXiv: 2407.00023},}
2023
Cloudless and Mixclaves
Vikranth
Srivatsa
EECS Department, University of California, Berkeley, May 2023
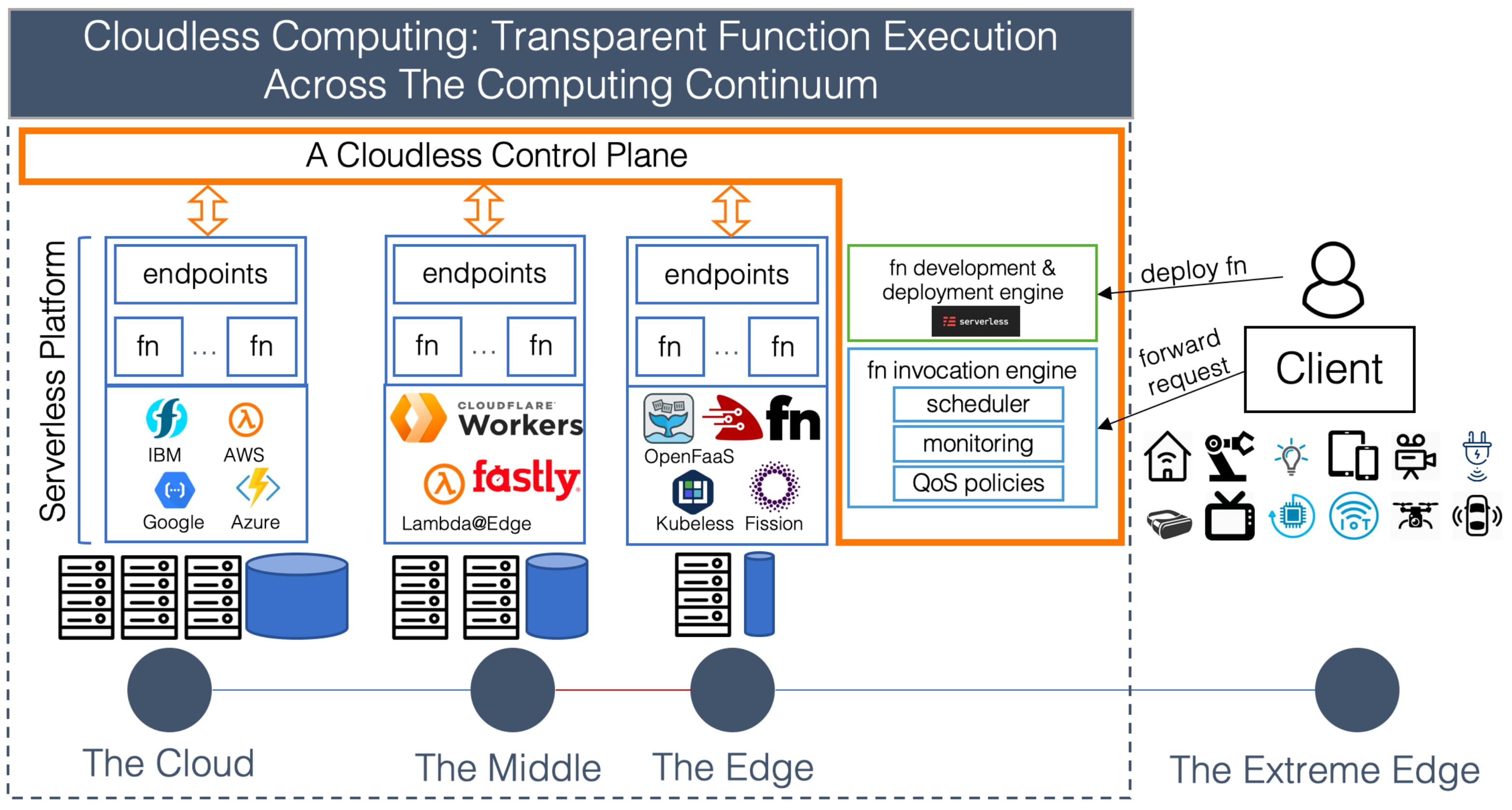
This thesis brings together two reports that focus on building a simplified secure compute abstraction across the cloud-edge. Cloudless is a serverless execution hierarchy that spans a multi-cloud to edge continuum and provides transparent function invocation across hybrid infrastructure. Cloudless provides a multi-cloud edge abstraction, enabling a simplified vendor-agnostic serverless computing model. Communicating with multiple regions brings about privacy concerns around authentication, anonymization, and integrity. Mixclaves is a metadata private messaging architecture that builds on hardware enclaves to provide a cost-efficient, low latency messaging service implementation deployable in public clouds. The work Cloudless and Mixclaves works towards the vision of an anonymous, cost-efficient, low latency, scalable computing paradigm that operates on multi-cloud and edge.
@mastersthesis{Srivatsa:EECS-2023-184,author={Srivatsa, Vikranth},title={Cloudless and Mixclaves},school={EECS Department, University of California, Berkeley},year={2023},month=may,url={http://www2.eecs.berkeley.edu/Pubs/TechRpts/2023/EECS-2023-184.html},number={UCB/EECS-2023-184},}
2021
The Effect of Model Size on Worst-Group Generalization
Alan Le
Pham, Eunice
Chan, Vikranth
Srivatsa, and
6 more authors
In NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications, May 2021
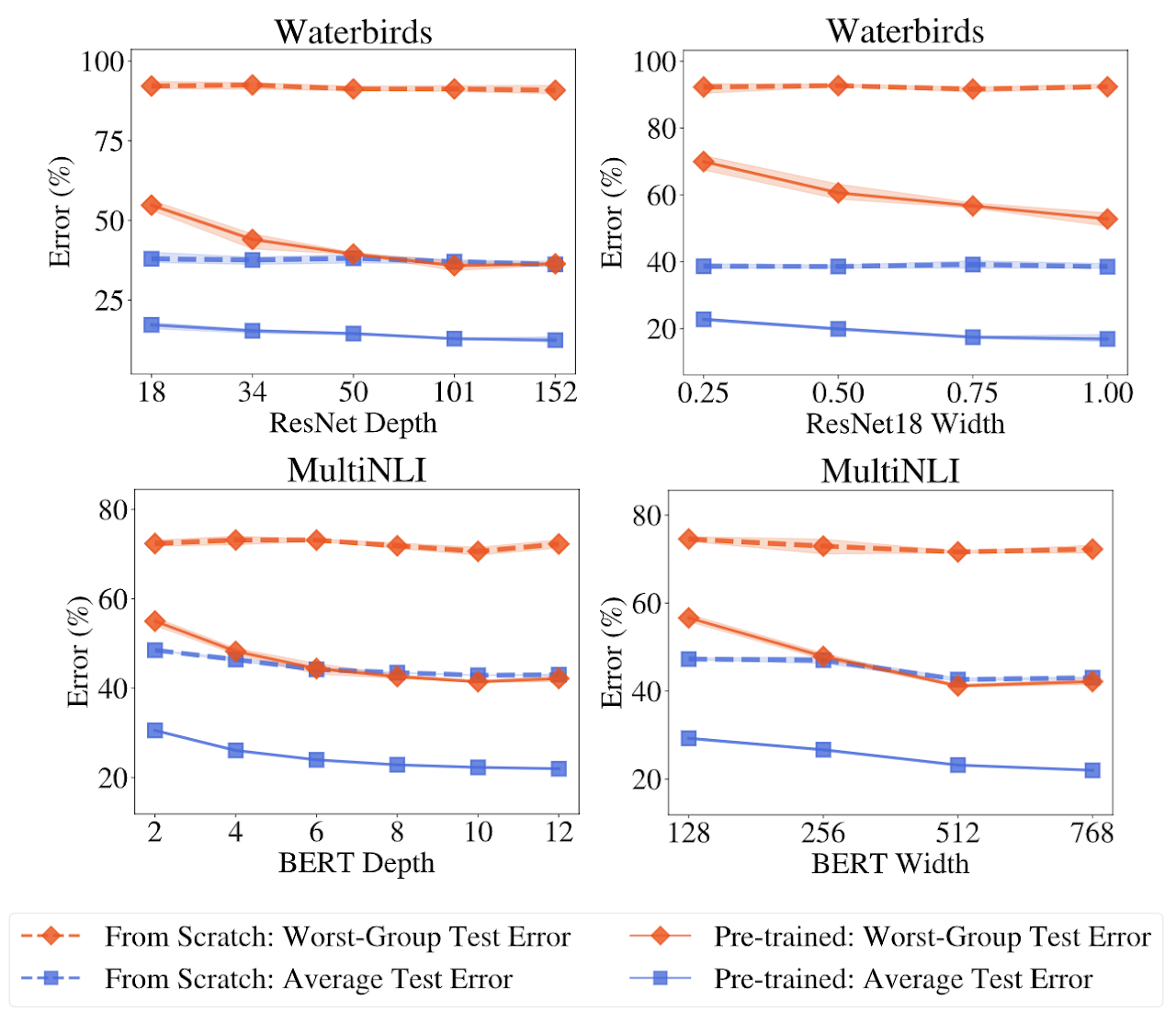
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
@inproceedings{pham2021the,title={The Effect of Model Size on Worst-Group Generalization},author={Pham, Alan Le and Chan, Eunice and Srivatsa, Vikranth and Ghosh, Dhruba and Yang, Yaoqing and Yu, Yaodong and Zhong, Ruiqi and Gonzalez, Joseph E. and Steinhardt, Jacob},booktitle={NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications},year={2021},url={https://openreview.net/forum?id=H8EF1LhFeqo},}